Anchor,为 锚点。
定义:锚点描述了在现实世界中一个固定的位置和方向,当用户想要放置一个虚拟物体时在平面上时,需要定义一个锚点来确保AR可以跟踪虚拟物体随用户运动推移所在的相对位置。基于锚点可以将虚拟物体锚定在现实空间中某一特定位置,进而实现用户可以从不同位置和角度进行观察。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1、选择性搜索(Selective Search)
先介绍一下传统的人脸识别算法,是怎么检测出图片中的人脸的?
以下图为例,如果我们要检测图中小女孩的人脸位置,一个比较简单暴力的方法就是滑窗,我们使用不同大小、不同长宽比的候选框在整幅图像上进行穷尽式的滑窗,然后提取窗口内的特征(例如Haar、LBP、Hog等特征),再送入分类器(SVM、Adaboost等)判断该窗口内包含的是否为人脸。这种方法简单易理解,但是这类方法受限于手动设计的特征,召回率和准确率通常不是很高。

大名鼎鼎的RCNN 和 Fast RCNN依旧依赖滑窗来产生候选框,也就是Selective Search算法,该算法优化了候选框的生成策略,但仍旧会产生大量的候选框,导致即使Fast RCNN算法,在GPU上的速度也只有三、四帧每秒。
直到Faster RCNN的出现,提出了RPN网络(Region Proposal Network),使用RPN直接预测出候选框的位置。用RPN代替Fast RCNN中Selective Search,RPN与object detection network共享卷积层,节省了大量选择候选区域的时间。
RPN网络一个最重要的概念就是anchor,启发了后面的SSD和YOLOv2等算法,虽然SSD算法称之为default box,也有算法叫做prior box,其实都是同一个概念,他们都是anchor的别称。
2、什么是Anchor ?
2.1 Anchor
anchor到底是什么呢?如果我们用一句话概括——就是在图像上预设好的不同大小,不同长宽比的参照框。(其实非常类似于上面的滑窗法所设置的窗口大小)
假设一个256x256大小的图片,经过64、128和256倍下采样,会产生4x4、2x2、1x1大小的特征图,我们在这三个特征图上每个点上都设置三个不同大小的anchor。
当然,这只是一个例子,实际的SSD模型,在300x300的输入下,anchor数量也特别多,其在38x38、19x19、10x10、5x5、3x3、1x1的六个特征图上,每个点分别设置4、6、6、6、6、4个不同大小和长宽比的anchor,所以一共有38x38x4+ 19x19x6+ 10x10x6+ 5x5x6+ 3x3x4+ 1x1x4= 8732个anchor。
在SSD中6层卷积层的每个特征图的每个中心点会产生2个不同大小的正方形默认框,另外每设置一个aspect_ratio则会增加两个长方形默认框,而文中代码对于6层的aspect_ratio个数分别为1、2、2、2、1、1,所以这也就是为什么会产生4、6、6、6、4、4个默认框了。
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]] 。paper中所给出的ar={1,2,3,1/2,1/3},这个比例是计算出来的。
我们不再需要计算Haar、Hog等特征,直接让神经网络输出,每个anchor是否包含物体(anchor与物体Bounding Box有较大重叠,交并比IoU(Intersection-over-Union,IoU)较大),以及被检测物体相对本anchor的中心点偏移以及长宽比例。
1、每个anchor认为自己是否含有物体的概率,
2、物体中心点与anchor自身的中心点位置的偏移量,
3、以及相对于anchor宽高的比例。
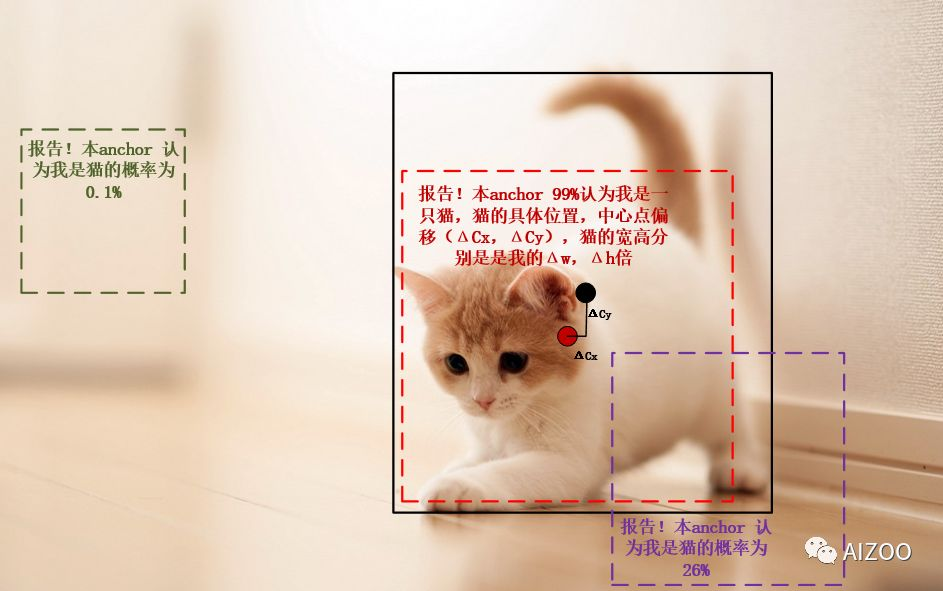
一般的目标检测网络可能有成千上万个anchor,例如标准SSD在300x300输入下有8732个anchor,在500x500下anchor数量过万。
因为anchor的位置都是固定的,所以就可以很容易的换算出来实际物体的位置。以图中的小猫为例,红色的anchor就以99%的概率认为它是一只猫,并同时给出了猫的实际位置相对于该anchor的偏移量,这样,我们将输出解码后就得到了实际猫的位置,如果它能通过NMS(非最大抑制,non-maximum suppression)筛选,它就能顺利的输出来。但是,绿色的anchor就认为它是猫的概率就很小,紫色的anchor虽然与猫有重叠,但是概率只有26%。
SSD的推理很简单,根据anchor进行位置解码,然后进行NMS过程,就完成了。
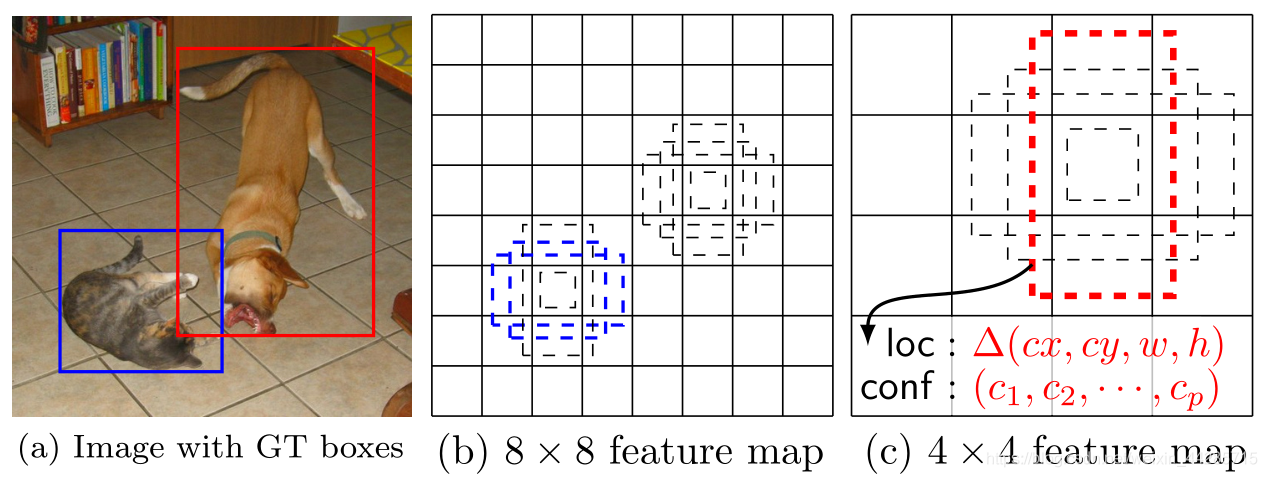
设置IoU阈值,例如大于0.5就认为是正样本,否则是负样本,(SSD算法中会给它强行分配一个IoU最大的anchor,即使IoU只有0.3)。因为anchor非常密集,所以SSD算法中,会有多个anchor与物体的IoU大于阈值,所以可能多个anchor都是对应同一个物体的正样本。图中的猫已经有了2个匹配的正样本(蓝色框)。
注意:在训练的时候,anchor的大小和长宽比应与待检测的物体尺度基本一致。
2.2 anchor_sizes从何而来?
2.2.1 FasterRCNN
FasterRCNN的RPN网络部分,anchor为三个尺度{128, 256, 512},三个比例{1:1, 1:2, 2:1},所以一共9组anchor。
2.2.2 SSD
在SSD论文中,作者使用6组定位层,(6个用于分类和回归的特征层(feature map),分别是'conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2'。每个定位层分别有6个anchor(不过第一和最后一个定位层只有4个)。一个尺度,分别有1:1、1:2、2:1、1:3、3:1五个不同宽高比,再加一个后面特征图的anchor尺度与该特征图的尺度相乘再开根号,也就是:
同样是1:1比例,所以一共5+1=6组anchor。
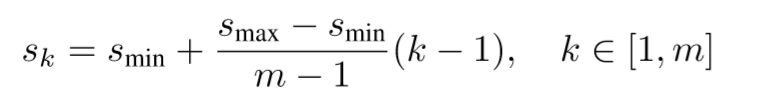
但是,大家查看SSD开源的代码,作者给出的得anchor大小并不是这么计算得到的。而是30、60、111、162、213、264(再加一个315)这7个尺度。
ssd_pascal.py
“#参数生成先验。
#输入图像的最小尺寸
min_dim = 300 #######维度
# conv4_3 ==> 38 x 38
# fc7 ==> 19 x 19
# conv6_2 ==> 10 x 10
# conv7_2 ==> 5 x 5
# conv8_2 ==> 3 x 3
# conv9_2 ==> 1 x 1
mbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2'] #####prior_box来源层,可以更改。很多改进都是基于此处的调整。
# in percent %
min_ratio = 20 ####这里即是论文中所说的Smin=0.2,Smax=0.9的初始值,经过下面的运算即可得到min_sizes,max_sizes。具体如何计算以及两者代表什么,请关注我的博客SSD详解。这里产生很多改进。
max_ratio = 90
####math.floor()函数表示:求一个最接近它的整数,它的值小于或等于这个浮点数。
step = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))####取一个间距步长,即在下面for循环给ratio取值时起一个间距作用。可以用一个具体的数值代替,这里等于17。
min_sizes = [] ###经过以下运算得到min_sizes和max_sizes。
max_sizes = []
for ratio in xrange(min_ratio, max_ratio + 1, step): ####从min_ratio至max_ratio+1每隔step=17取一个值赋值给ratio。注意xrange函数的作用。
########min_sizes.append()函数即把括号内部每次得到的值依次给了min_sizes。
min_sizes.append(min_dim * ratio / 100.)
max_sizes.append(min_dim * (ratio + step) / 100.)
min_sizes = [min_dim * 10 / 100.] + min_sizes
max_sizes = [min_dim * 20 / 100.] + max_sizes
steps = [8, 16, 32, 64, 100, 300] ###这一步要仔细理解,即计算卷积层产生的prior_box距离原图的步长,先验框中心点的坐标会乘以step,相当于从feature map位置映射回原图位置,比如conv4_3输出特征图大小为38*38,而输入的图片为300*300,所以38*8约等于300,所以映射步长为8。这是针对300*300的训练图片。
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]] #######这里指的是横纵比,六种尺度对应六个产生prior_box的卷积层。具体可查看生成的train.prototxt文件一一对应每层的aspect_ratio参数,此参数在caffe.proto中有定义,关于aspect_ratios如何把其内容传递给了aspect_ratio,在model_libs.py文件中有详细定义。
##在此我们要说明一个事实,就是文中的长宽比是如何产生的,这里请读者一定要参看博主博文《SSD详解(一)》中的第2部分内容,关于prior_box的产生。”
(1)对ssd产生的默认框的大小计算首先要计算参数min_sizes和max_sizes
step的作用,其实就是取一个间隔
首先定义数组min_sizes[]和max_sizes[]用来存放计算结果,没有初始化说明默认为0,。然后计算conv4_3产生的min_sizes和max_sizes。根据代码中的公式计算:
·min_sizes=[min_dim*10/100]+min_sizes
·max_sizes=[min_dim*20/100]+max_sizes
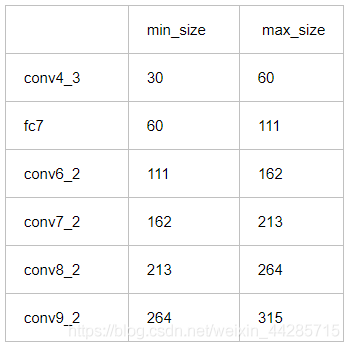
得到结果为min_sizes=[300*10/100]+0=30,而max_sizes=[300*20/100]+0=60。这样conv4_3的计算公式被计算分别为30和60。
在min_ratio和max_ratio之间即20-90之间以step=17为间隔产生一组数据赋值给ratio,最终ratio=[20,37,54,71,88]。所以对于剩余5层所产生的min_sizes和max_sizes分别为:
fc7:min_sizes=min_dim*ratio/100=300*20/100=60,max_sizes=min_dim*(ratio+step)/100=300*(20+17)/100=111;
conv6_2:min_sizes=min_dim*ratio/100=300*37/100=111,max_sizes=min_dim*(ratio+step)/100=300*(37+17)/100=162;
conv7_2:min_sizes=min_dim*ratio/100=300*54/100=162,max_sizes=min_dim*(ratio+step)/100=300*(54+17)/100=213;
conv8_2:min_sizes=min_dim*ratio/100=300*71/100=213,max_sizes=min_dim*(ratio+step)/100=300*(71+17)/100=264;
conv9_2:min_sizes=min_dim*ratio/100=300*88/100=213,max_sizes=min_dim*(ratio+step)/100=300*(88+17)/100=315;
结果:7个数据,6个区间段
(2)产生的默认框的大小计算
·正方形小边长=min_size
·而大正方形边长=sqrt(min_size*max_size)
·width=sqrt(aspect_ratio)*min_size
·height=1/sqrt(aspect_ratio)*min_size
对其高和宽翻转后得到另一个面积相同但宽高相互置换的长方形(width和height公式对调)。
现在我们可以计算6层中每个特征图的每个中心点所产生的默认框的大小,分别如下:
conv4_3:
小正方形边长=min_size=30,大正方形边长=sqrt(min_size*max_size)=sprt(30*60)=42.42;
长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(2)*30,高=1/sqrt(aspect_ratio)*min_size=30/sqrt(2),宽高比刚好为2:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:2。
fc7:
小正方形边长=min_size=60,大正方形边长=sqrt(min_size*max_size)=sprt(60*111)=81.6;
第1组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(2)*60,高=1/sqrt(aspect_ratio)*min_size=60/sqrt(2),宽高比刚好为2:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:2。
第2组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(3)*60,高=1/sqrt(aspect_ratio)*min_size=60/sqrt(3),宽高比刚好为3:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:3。
conv6_2:
小正方形边长=min_size=111,大正方形边长=sqrt(min_size*max_size)=sprt(111*162);
第1组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(2)*111,高=1/sqrt(aspect_ratio)*min_size=111/sqrt(2),宽高比刚好为2:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:2。
第2组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(3)*111,高=1/sqrt(aspect_ratio)*min_size=111/sqrt(3),宽高比刚好为3:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:3。
1、anchor_size, 这个参数直接决定了当前特征层的box 的大小, 可以看出越靠近输入层, box越小, 越靠近输出层, box越大, 所以 SSD的底层用于检测小目标, 高层用于检测大目标。
2、conv7_2、conv8_2、conv9_2我们这里就不再计算了,具体实现的步骤请大家参考脚本prior_box_layer.cpp
3、另外先验框与ground truth框的匹配通过函数CHECK_GT()函数实现,具体在bbox_util.cpp脚本中实现
附:tensorflow实现的SSD的源码:
default_params = SSDParams(
img_shape=(300, 300),
num_classes=21,
no_annotation_label=21,
feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],
# anchor_size_bounds=[0.15, 0.90],
anchor_size_bounds=[0.20, 0.90],
#anchor_sizes=[(21., 45.),
# (45., 99.),
# (99., 153.),
# (153., 207.),
# (207., 261.),
# (261., 315.)],
anchor_sizes=[(30., 60.),
(60., 111.),
(111., 162.),
(162., 213.),
(213., 264.),
(264., 315.)],
anchor_ratios=[[2, .5],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5],
[2, .5]],
anchor_steps=[8, 16, 32, 64, 100, 300],
anchor_offset=0.5,
normalizations=[20, -1, -1, -1, -1, -1],
prior_scaling=[0.1, 0.1, 0.2, 0.2]
)
2.2.3 YOLOv3
在三个不同尺度,每个尺度三个不同大小的anchor,一共九组。
2.3 anchor_ratios
anchor_ratios,定义了anchor的宽高比,这里设置anchor_rations = [0.5, 1, 2]。
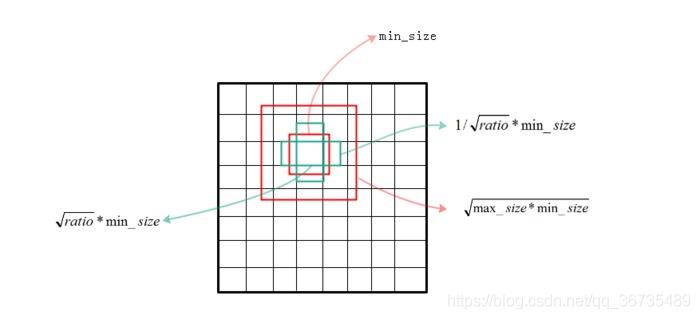
需要注意的是宽高比变化的同时保持面积不变。对于 base_size = 16 的情况下:
·ratio为0.5时,尺寸为 (16/sqrt(2)) x (16*sqrt(2)),即 11 x 22;(宽 × 高)
·ratio为1时,anchor尺寸为16 x 16;
·ratio为2时,尺寸为 23 x 12 。
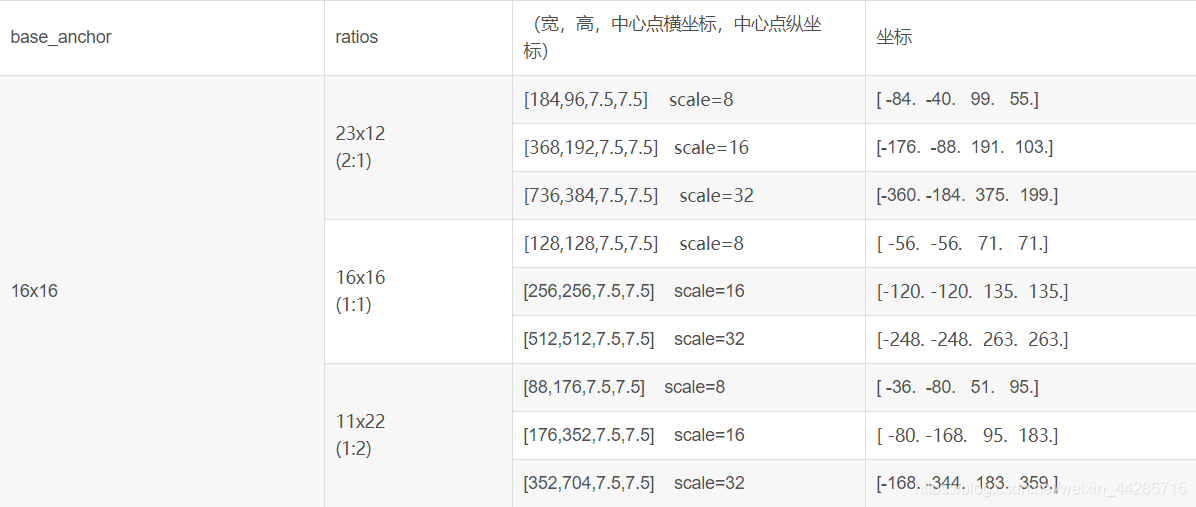
得到的anchor如下图所示,蓝色点代表feature map中的特征点,每种颜色框代表一种长宽比,同一颜色不同大小的矩形框代表不同的尺度:
红色:ration = 2
蓝色:ration = 1
绿色:ration = 0.5
坐标顺序为:左下右上。
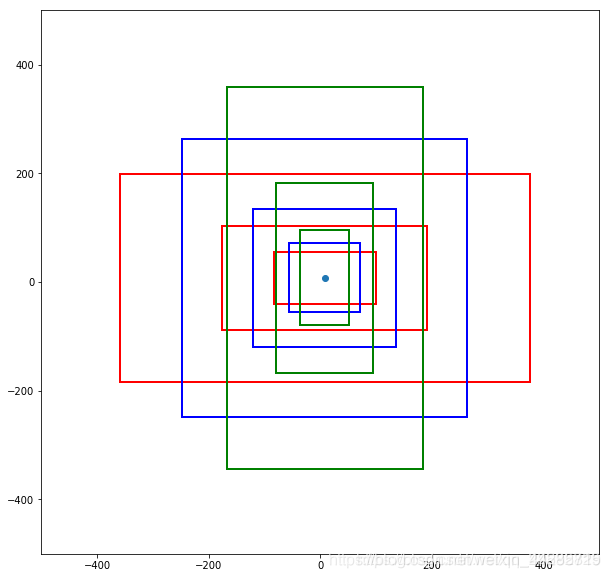
附:anchors 的生成过程(generate_anchors源码解析)
import numpy as np
import time
def generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2**np.arange(3, 6)):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window.
scales = [8, 16, 32]
16x16的区域变成(16*8)*(16*8)=128*128的区域,(16*16)*(16*16)=256*256的区域,(16*32)*(16*32)=512*512的区域
"""
# 表示最基本的一个大小为16x16的区域,四个值,分别代表这个区域的左上角和右下角的点的坐标。
base_anchor = np.array([1, 1, base_size, base_size]) - 1
print ("base anchors", base_anchor)
# 这一句是将前面的16x16的区域进行ratio变化,也就是输出三种宽高比的anchors,这里调用了_ratio_enum函数
ratio_anchors = _ratio_enum(base_anchor, ratios)
print ("anchors after three ratio \n", ratio_anchors)
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in range(ratio_anchors.shape[0])])
print ("achors after ration and scale \n", anchors)
return anchors
def _ratio_enum(anchor, ratios):
'''
Enumerate a set of anchors for each aspect ratio wrt an anchor.
Parameters:
anchor : A list contains coordinates of the upper left and lower right corners.
ratios : A list contains different aspect ratios.
Return:
anchors : Coordinates with different aspect ratios.
'''
w, h, x_ctr, y_ctr = _whctrs(anchor)
size = w * h #size:16*16=256
size_ratios = size / np.array(ratios) #256/ratios[0.5,1,2]=[512,256,128]
ws = np.round(np.sqrt(size_ratios)) #ws:[23 16 11]
hs = np.round(ws * ratios) #hs:[12 16 22],ws和hs一一对应。as:23*12、16*16、11*22,(高 × 宽)
# print(hs)
# print(ws.shape)
# 给定一组宽高向量,输出各个预测窗口,也就是将(宽,高,中心点横坐标,中心点纵坐标)的形式,转成四个坐标值的形式
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
def _whctrs(anchor):
"""
主要作用是将输入的anchor的四个坐标值[0, 0, 15, 15]转化成(宽,高,中心点横坐标,中心点纵坐标)的形式。
Return width, height, x center, and y center for an anchor (window).
"""
w = anchor[2] - anchor[0] + 1# w = 16
h = anchor[3] - anchor[1] + 1# h = 16
x_ctr = anchor[0] + 0.5 * (w - 1)# 7.5
y_ctr = anchor[1] + 0.5 * (h - 1)# 7.5
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr):
"""
Getting coordinates of different window width ratios around the same center.
Parameters:
ws : A sist of X coordinates in the upper left corner of a anchor.
hs : A sist of Y coordinates in the upper left corner of a anchor.
x_ctr : X-coordinates of the center of a anchor.
y_ctr : Y-coordinates of the center of a anchor.
Return:
anchors : Coordinates with different aspect ratios.
"""
ws = ws[:, np.newaxis]# ws的维度变为[3,1],即[[23]
# [16]
# [11]]
# print(ws)
# print(ws.shape)
hs = hs[:, np.newaxis]# hs同理
anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)))
return anchors
def _scale_enum(anchor, scales):
"""
_enum表示枚举,以_ratio_enum(...)得到的3个anchor,得到其中心点和宽、高值,并将宽、高值与3个scale相乘(保持中心点不变),
最终得到9个在scaled图像中(0,0)位置的base anchors,被generate_anchors(...)调用
Enumerate(枚举) a set of anchors for each scale wrt an anchor.
Parameters:
anchor : Orginal anchor.
scales : Scaling factor.
Return:
Scaled coordinates of anchor.
"""
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
if __name__ == '__main__':
import time
t = time.time()
a = generate_anchors() #最主要的就是这个函数
print("it takes time:", time.time() - t)
补充:
SSD中min_size&max_size的另一种计算方法(来自网上,不知道是否正确):
在SSD中,作者提到了anchor尺度大小(scale)的计算方法,也就是从最小的0.2,到最大的0.9,中间四个定位层的大小是等间隔采样得到的。
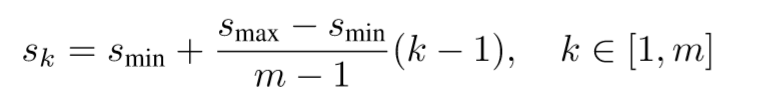
Sk是每个特征层的先验框大小与原图片大小之比,Smax和Smin分别是最大,最小的比例.
m是就是特征层的个数,按理说分母应该是6-1=5,但是这里是5-1=4.很神奇。
k是第几个特征层的意思,注意k的范围是1~m, 也就是1~6.
需要向下取整
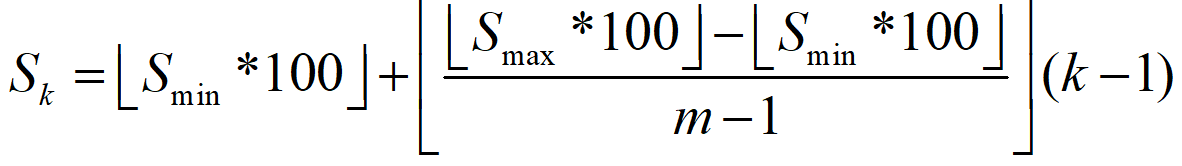
将m=5, Smin, Smax=(0.2, 0.9) 就是anchor_size_bounds=[0.20, 0.90],带入之后,得到S1~S6: 20, 37, 54, 71, 88, 105, 其实就是挨个+17。此时还需要将其除以100还原回来,也就是:0.2, 0.37, 0.54, 0.71, 0.88, 1.05。然后,我们这个是比例,我们需要得到其在原图上的尺寸,所以需要依次乘以300,得到:60, 111, 162, 213, 264, 315。
最后,你会问: 30呢? 这就要说到S1’了,S1’=0.5*S1, 就是0.1, 再乘以300, 就是30.
有七个数, 6个区间段, 目的还是为了得到上面那6组min_size和max_size. 就可以计算每个特征层的anchor_box 的尺寸了。
我想这应该是作者根据数据集的物体框大小的分布而设置的。因为上面我们介绍了,anchor只有跟你要检测的物体的大小和长宽比更贴近,才能让模型的效果更好。
延伸阅读来源:https://blog.csdn.net/weixin_44285715/article/details/105124650














